
반응형
중복된 문장 찾기, uniq
리눅스에서 uniq 명령어는 텍스트 파일의 연속된 중복 라인을 필터링하는 데 사용됩니다. 일반적으로 uniq는 sort 명령어의 출력 결과에 사용되어 중복된 라인을 제거하고 유일한 라인만을 출력합니다. uniq는 파일에서 중복된 라인을 찾아내거나 중복된 라인의 수를 세는 등 다양한 방식으로 활용될 수 있습니다.
기본 사용법
uniq 명령어의 기본 구문은 다음과 같습니다:
uniq [옵션] [입력_파일 [출력_파일]]만약 입력 파일이 지정되지 않거나 -로 지정되면, uniq는 표준 입력에서 읽어 들입니다. 출력 파일이 지정되지 않으면 표준 출력으로 결과가 출력됩니다.
주요 옵션
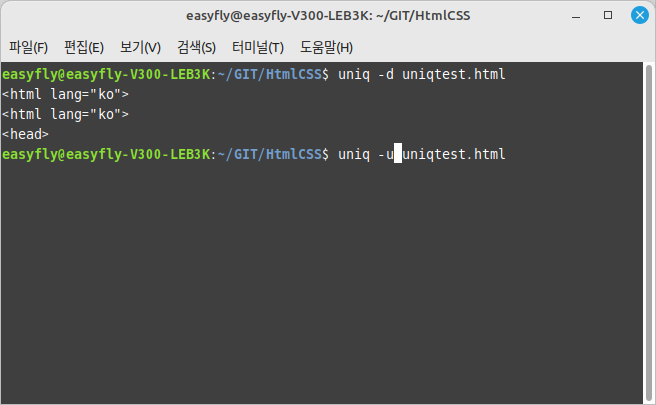
-c,--count: 각 라인이 나타난 횟수를 출력합니다.-d,--repeated: 중복된 라인만을 출력합니다.-u,--unique: 중복되지 않은 라인만을 출력합니다.-i,--ignore-case: 대소문자를 구분하지 않고 라인을 비교합니다.
예시
- 파일에서 연속된 중복 라인을 제거:
uniq 입력_파일 - 중복된 라인의 수를 세기:
uniq -c 입력_파일 - 중복된 라인만 출력하기:
uniq -d 입력_파일 - 중복되지 않은 라인만 출력하기:
uniq -u 입력_파일
정리
uniq는 중복된 라인을 필터링하는 명령어입니다.- 주로 정렬된 파일에서 사용되어 유일한 라인을 추출합니다.
- 다양한 옵션을 통해 중복된 라인의 처리 방식을 조정할 수 있습니다.
uniq 명령은 텍스트 데이터를 분석하거나 처리할 때 유용하게 사용될 수 있으며, 특히 로그 파일이나 데이터 세트에서 유일한 항목을 찾아내는 데 자주 활용됩니다. 연속된 중복 라인을 찾아내기 때문에, 전체 파일에서 중복을 제거하고자 한다면 먼저 sort 명령어를 사용하여 파일을 정렬한 후 uniq를 사용하는 것이 일반적입니다.
반응형
'Linuxpia > Linux 명령어' 카테고리의 다른 글
| [리눅스 명령어] 사용자 계정 정보 수정, usermod (139) | 2024.02.08 |
|---|---|
| [리눅스 명령어] 사용자 계정 만들기, useradd (130) | 2024.02.07 |
| [리눅스 명령어] 공백 문자를 탭으로 변환, unexpand (145) | 2024.02.05 |
| [리눅스 명령어] 시스템 정보 보기, uname (149) | 2024.02.04 |
| [리눅스 명령어] 별명 제거하기, unalias (98) | 2024.02.03 |