
반응형
텍스트 관련 명령어
텍스트 관련 명령어에는 cat, head, tail, more, less, grep, wc, sort, cut, split 등이 있다.
cat
- 텍스트 파일의 내용을 보거나 텍스트 파일을 다른 새로운 파일로 복사하거나 또는 기존의 텍스트 파일과 합치는 기능을 수행한다.
- 형식: cat [option] file
- 옵션
- -b, --number-nonblank: 빈 줄을 제외하고 행 번호를 붙여준다.
- -n, --number: 모든 줄에 행 번호를 붙인다.
- -E, --show-ends: 각 줄의 끝에 '$'를 표시한다.
- -T, --show-tabs: 탭 문자로 '^'로 표시한다.
- -v --show-nonprinting: 인쇄 불가한 문자도 표시한다.
- -A, --show-all: -vET 명령어와 동일하다.
- -s, --squeeze-blank: 반복되는 빈 줄은 무시한다.
- 예제
- cat readme.txt와 cat < readme.txt
- cat readme.txt readme2.txt
- cat readme.txt > newreadme.txt
- cat readme.txt >> another-readme.txt
head
- 지정한 파일의 앞 부분을 출력한다. 옵션을 지정하지 않는다면 첫 10줄을 출력한다.
- 형식: head [option] file
- 옵션
- -n, --lines: 출력할 줄 수 지정한다. 만약 숫자 앞에 '-'를 붙이면 모두 출력하되 지정한 바이트 수만큼 마지막에 출력하지 않는다.
- -c, --type: 출력한 바이트 수를 지정한다. 만약 숫자 앞에 '-'를 붙이면 모두 출력하되 지정한 바이트 수만큼 마지막에 출력하지 않는다.
- 예제
- head readme.txt
- head -n 5 readme.txt
- head -5 readme.txt
- head -n -5 readme.txt
tail
- 지정한 파일의 끝 부분을 출력한다. 옵션을 지정하지 않으면 10줄만 출력한다. 보통 로그 파일이나 실시간 이벤트 확인 시 최근의 정보를 확인할 때 유용하다.
- 형식: tail [option] file
- 옵션
- -n, --lines: 파일의 마지막에서 지정한 줄만큼 출력한다.
- -c, --bytes: 파일의 마지막에서 지정한 바이트 수만큼 출력한다.
- -f, --follow: 새로운 데이터가 들어올 때까지 모니터링한다. 데이터가 추가되면 출력하기를 반복한다.

more
- 텍스트 파일의 내용이 많을 때 한 페이지씩 보여주는 명령어이다.
- 형식: more [option] file
- 옵션
- -num: 스크린에 한 번에 보여줄 줄 수를 설정한다.
- 예제
- more /etc/passwd
- more -10 /etc/passwd
- cat /etc/passwd | more
less
- more 명령어와 같이 텍스트의 파일 내용을 페이지 단위로 보여주는 명령어이다. more 명령어와 달리 다양한 옵션을 제공한다. 또한 vi 명령어와 같이 프로그램 시작 전 텍스트 파일을 모두 읽어 메모리에 올리지 않기 때문에 프로그램 시작이 빠르다. 커서 키나 마우스 휠을 이용해서 화면 이동이 가능하고 vi에서 익숙한 명령어도 사용이 가능하다.
- 형식: less [option] file
- 옵션
- -c, --clear-screen: 화면을 지우고 최상단부터 결과를 출력한다.
- -s, --squeeze-blank-lines: 연속된 빈 줄을 합쳐 하나의 빈줄로 만든다.
- -e: 파일 끝에서 한번 더 파일 끝으로 이동하면 자동으로 프로그램이 종료된다. 기본 동작은 'q' 명령어에 의해 종료된다. 'q'는 'quit'의 머리글자이다.
- -N: 각 줄마다 행 번호를 함께 출력한다.
- 예제
- less /var/log/dmesg
- less -N /var/log/dmesg
- less +80 /var/log/dmesg
grep
- 텍스트 파일을 한 줄식 읽어서 지정한 패턴과 일치하는 문자열을 보여주는 명령어이다.
- 형식: grep [option] pattern file ···
- 옵션
- -b, --byte-offset: 지정한 패턴과 일치하는 줄의 offset을 줄 앞에 출력한다. 만약 -o 옵션과 함께 사용하면 패턴과 일치하는 위치마다 offset을 출력한다.
- -c, --count: 패턴과 일치하는 줄이 몇 줄인지 표시한다.
- -h, --no-filename: 파일 이름을 출력하지 않는다.
- -I, --ignore-case: 패턴과 입력 파일 모두 대소문자를 구분하지 않는다.
- -n, --line-number: 출력 결과에 1부터 시작하는 행 번호를 붙인다.
- -v, --invert-match: 패턴과 매칭되지 않는 항목을 출력한다.
- -w, --word-regexp: 패턴과 한 단어가 일치하는 줄을 출력한다.
- -x, --line-regexp: 패턴과 전체 줄과 일치할 때 출력한다.
- -l, --files-with-matches: 정상적인 파일 출력 대신에 파일 이름을 출력한다.
- -r, --recursive: 지정한 디렉터리의 모든 파일에 대하여 패턴을 찾는다.
- -o, --only-matching: 패턴과 일치하는 부분만 출력한다.
- -E, --extende-regexp: 패턴을 확장 정규식으로 사용한다.
- -F, --fixed-strings: 패턴을 고정된 문자열의 리스트로 사용한다.
- 예제
- grep msi /etc/passwd
- cat /etc/passwd | grep msi
- grep -r msi /home/
- grep -w msi /etc/passwd
- grep -w msi /etc/group
- grep -c msi /etc/passwd
- sudo grep -lr msi /etc

정규 표현식으로 패턴 지정
- 특정한 규칙을 가진 문자열의 집합을 표현하는 일종의 형식 언어이다. 주로 문자열 검색 및 치환할 때 사용한다.
- .: 하나의 문자와 매칭한다.
- a*: a라는 문자가 없거나, a, aa, aaa 등 여러 개일 수 있다. 가령 ca*의 경우 cr, car, caar, caaar 등이 매칭된다.
- [abc]: 어떤 문자열이라도 a, b, c 중 하나라도 포함하면 매칭된다.
- [^abc]: 어떤 문자열이 a, b, c를 포함하고 있지 않으면 매칭된다.
- [a-zA-Z]: a~z 또는 A~Z의 문자열만 매칭된다.
- th(e|is|at): the, this, that과 같은 문자열과 매칭된다.
- '^pattern': 지정한 패턴으로 줄이 시작하는 경우 매칭된다.
- 'pattern$': 지정한 패턴으로 줄이 끝나는 경우 매칭된다.
- '\<pattern': 지정한 패턴으로 단어가 시작하는 경우 매칭된다.
- 'pattern\>': 지정한 패턴으로 단어가 끝나는 경우 매칭된다.
- grep "[a-z]" readme: 소문자 a~z를 포함하는 줄을 모두 출력한다.

wc
- 지정한 파일에 대해 줄, 단어, 문자의 개수 등을 셀 수 있는 명령어이다.(word count에서 나옴)
- 형식: wc [option] file
- 옵션
- -l, --lines: 줄 수를 센다.
- -w, --words: 단어의 개수를 센다.
- -c, --bytes: 바이트 수를 센다.
- -L, --max-line-length: 가장 긴 줄의 길이를 출력한다.

sort
- 텍스트 파일을 한 줄씩 읽어서 정렬하는 프로그램이다.
- 형식: sort [option] file
- 옵션
- -b, --ignore-leading-blanks: 공백은 무시한다.
- -d, --dictionary-order: 오직 공백과 알파벳 문자만을 대상으로 정렬한다.
- -f, --ignore-case: 대소문자 구분을 하지 않는다.
- -r, --reverse: 정렬 결과를 반대로 출력한다.
- -o, --output: 출력 결과를 지정한 파일에 저장한다.
- -c, --check: 입력 값이 정렬되어 있는지 체크한다. 실제로 정렬하지는 않는다.
- -n, --numeric-sort: 숫자를 문자가 아닌 숫자 값으로 정렬한다.
- -u, --unique: 줄이 중복되면 처음 하나만 출력한다.
- -M, --month-sort: 월 표시 문자를 인식하여 정렬한다. 가령 'JAN' < 'FEB' < ... < 'DEC'와 같은 순으로 정렬된다.
- -t, --field-seperator: 이 옵션을 통해 필드 구분자를 변경할 수 있다. 기본 값은 공백이다.
- -k, --key: 정렬할 필드를 정한다.
- 예제
- sort -r test
- sort -r test -o test2
- sort -k 3 test
- sort -k 3.3 test
cut
- 텍스트 파일을 한 줄 또는 여러 줄을 잘라낼 수 있는 명령어이다.
- 형식: cut [option] file ...
- 옵션
- -c, --characters: 각 줄의 문자를 선택한다.
- -f, --fields: 각 줄의 필드를 선택한다.
- -d, --delimiter: 필드 구분자를 변경한다. 기본값은 TAB이다.
- 예제
- cut -c 1-3 test
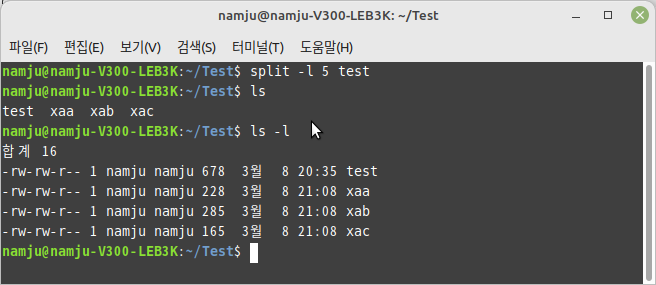
split
- 파일을 고정 크기의 여러 파일로 분할하는 명령어이다.
- 형식: split [option] file [file_name]
- 옵션
- -b, --byte: 각 파일당 저장할 크기를 지정한다.
- -C, --line-bytes: 각 파일당 행의 크기를 주어진 값에 맞춰서 쓴다.
- -l, --lines: 각 파일당 줄 수를 지정한다.
반응형
'Linux > 리눅스 시스템 관리' 카테고리의 다른 글
| 02_02_파일 시스템 점검 (0) | 2022.03.10 |
|---|---|
| 02_01_파일 시스템 관리 및 복구 (0) | 2022.03.10 |
| 01_02_05_파일 시스템 관리_파일 관리 (0) | 2022.02.20 |
| 01_02_04_파일시스템 관리_디렉터리 관리 (0) | 2022.02.15 |
| 01_02_03_리눅스 파일 시스템 관리_파일 링크 (0) | 2022.02.14 |